I’m mostly retired, but still consult a bit in my field: Intelligent Transportation Systems (the use of advanced sensors, communications and information processing systems to improve ground transportation). The field includes connected and automated vehicles. And out of intellectual curiosity, I’ve also been learning about sentiment analysis. So I decided to combine these interests by tracking the change in sentiment over time, about automated vehicles, using tweets as the source material. And while I was at it, I figured I’d do the same thing for electric vehicles, and publicly display the results on two web pages.
One of the common, basic approaches to sentiment analysis is to determine whether the general tone of a sample of text is positive, negative, or neutral. That is the approach that I’ve taken. To determine this, one can use a rules-based approach, where certain words and word combinations are assigned tones and intensity (e.g., “hate” is very negative, “cool” is positive, “not cool” is negative). The scores for each sentiment word are combined to get an overall sentiment for the text sample. The other approach is to use machine learning algorithms to determine the sentiment. This approach can be more flexible, but requires a lot of training data, and the training data must be tagged by humans. In addition, multiple humans should review each sample, as studies have shown that humans can disagree with one another 20% of the time when assigning sentiment to a text sample.
I decided to use tweets posted on Twitter as the source material, since there are a large number of new entries every day and Twitter provides a free API that allows one to sample thousands of tweets per day, filtered by keywords and other parameters.
Once each tweet is assigned a sentiment value, I look at several metrics based on the total numbers of positive, negative, and neutral tweets. In addition, I extract and save the 100 most common 1 word and 2-word combinations found in the set of tweets for the day. The results are then used to generate several metrics, plots, and displays for the web pages.
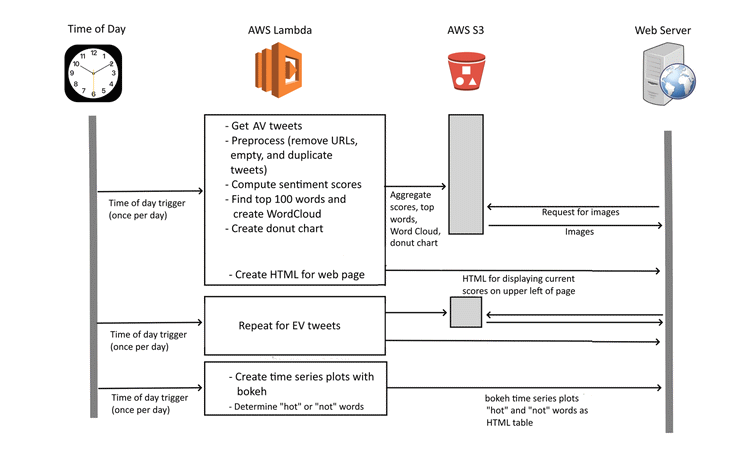
The overall system for data collection, analysis, and display is shown…
Getting and Filtering Tweets
The first step is to get the relevant tweets and clean and filter them. Two almost identical programs are used, one for AV tweets and one for EV tweets. The reason these are not combined into a single program is that this would exceed the 15 minute access limit of Twitter’s API. Instead, each is run once, about an hour apart, during the middle of the night eastern standard time.
Twitter’s free “Essentials” access level lets one search through a sample of tweets that were posted in the last 7 days. In order to access the twitter API, one must first register. Then, I used tweepy, a free python library for accessing the Twitter API. The search query API provides for a large number of query parameters. For this project, I searched for tweets containing any of a list of key words and that were not retweets, replies, or quote tweets (i.e., only original tweets are included).
The search terms were selected to try to broadly collect relevant tweets, but to avoid accidentally capturing a significant number of irrelevant ones. For example, the AV search terms include “self driving,” “automated vehicles,” and “automated shuttles” but does not include “Tesla,” as many tweets with the word Tesla are about the stock price or other aspects of the company, not about autonomous vehicles.
The next steps filtered out empty tweets and remove URLs from the tweet contents. During development, manual inspection revealed a large number of identical or nearly identical tweets, mostly originating from bots that pick up and tweet news stories. Therefore a filter was set up to keep only one sample from these duplicates and near-duplicates. To remove exact duplicates I simply used the drop_duplicates method in pandas. Removing near duplicates proved more problematic. The basic approach is to assess the similarity between pairs of tweets, and if they are sufficiently similar, remove one of them. Unfortunately this involves comparing every tweet with every other tweet, and there are thousands of tweets. I found that efficiently iterating through the tweets required the use of pandas’ itertuples method. This was at least an order of magnitude faster than using iterrows or items methods. Even so, the first similarly library I tried to use, SequenceMatcher, took over 10 minutes to perform all the comparisons! In the end, I used the Levenshtein.normalized_similarity method from the RapidFuzz library. This brought the runtime down to seconds.
Sentiment Analysis
The filtered and cleaned up tweets were now each analyzed to determine the sentiment of the tweets. I experimented with a number of approaches and settled on using VADER, an open-sourced, rule-based tool for sentiment analysis, written in Python. VADER was specifically developed to analyze short social media posts, such as tweets. In addition, it runs very quickly, which is useful as I analyze thousands of tweets at a time on each of the two subjects.
I made two very minor changes to the VADER code. First, as reported in the “issues” on GitHub, some words are listed more than once in it’s dictionary, with differing sentiment values. For these, I used my best judgement on which to keep and discarded the duplicates. In addition, VADER lets the user add their own words to its dictionary of sentiments. Based on manual review of a large number of tweets, some additional words tailored to the subject matter were added and assigned sentiments:
- “advances”: 1.2
- “woot”: 1.8
- “dystopia”: -2.5
- “dystopian”: -2.5
- “against”: -0.9
- “disaster”: -2.5
Sentiment Metrics
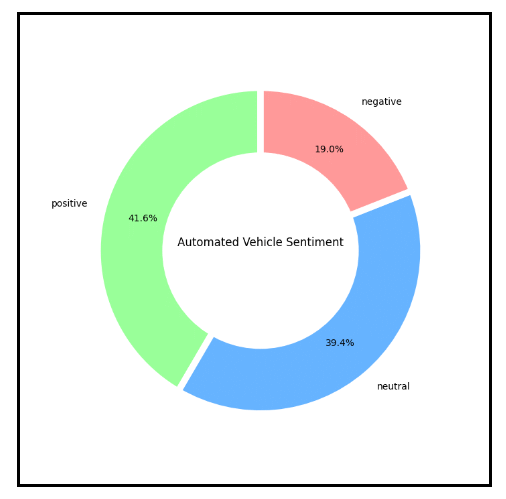
Once the sentiment of each tweet is determined, the results are aggregated. The total numbers of negative, positive, and neutral counts are calculated and stored in an AWS S3 storage bucket. Using matplotlib’s pyplot, a donut graph is created showing the percentages for each type of sentiment, and the graph is also stored in an S3 bucket for display on the web pages.
Two indices are also calculated: the ratio of the number of positive to negative tweets, ignoring neutral tweets, and the index, which is the average value, with each negative tweets counting as -1, neutral tweets as 0, and positive tweets as +1. These scores are put into an HTML fragment and transferred to the web server for incorporation into the two sentiment indices web pages.
Word Cloud

In addition to calculating the sentiment indices, the 100 most common single and two-word combinations are determined for the current days tweets. A word cloud image is also generated. Both of these are done using the WordCloud library. Both the word list and the Word Cloud are written out to one of the S3 buckets.
Time Series Charts with Bokeh
After both of the sentiment analysis programs are run each day, a single additional program is run. This program has two functions, each of which operate separately on the AV and EV data. First, it produces two time series plots of the sentiment indices, using the data stored in one of the S3 buckets. Second, it uses the most common words stored in S3 bucket and compares them with the list that was stored in the bucket 7 days ago. Words that appear in the most common 100 for the current day, but not the day a week ago are determined (“hot” words), as well as those that were on the list 7 days ago, but not today (“not” words). A subset of the list is then formatted into an HTML table for display on the web pages.
Bokeh is used to generate the two time series plots. I used bokeh rather than matplotlib because I wanted some interactivity on the web page, and Bokeh is a Python library for creating interactive visualizations for web browsers. The actual web scripts that Bokeh generates are in javascript.
This was my first time using Bokeh. It wasn’t hard to figure out how to generate the basic time series plots that I wanted, or to add the “hover” tool to allow one to see the value of particular data points. However, I had some trouble figuring out how to generate the results for use on a web page and then incorporating them in the page. Bokeh plots can require a server, for complex interactivity involving changing data or plots, or can be embedded as standalone plots. For this application, I used it in standalone mode. There are four modes that can be used for this, and as a beginner, I freely confess I don’t understand them well.
The file_html method returns a complete HTML document that embeds the Bokeh documents. That wouldn’t be appropriate for this application, as the Bokeh plots are embedded within other web pages. The json_item method “returns a JSON block that can be used to embed standalone Bokeh content.” I played around with this a bit, but I don’t really understand it. The components method returns “Return HTML components to embed a Bokeh plot. The data for the plot is stored directly in the returned HTML.” I didn’t explore this one at all. Finally, the autoload_static method returns “JavaScript code and a script tag that can be used to embed Bokeh Plots. The data for the plot is stored directly in the returned JavaScript code.” This is what I used. The method returns a tuple consisting of JavaScript code to be saved and a <script> tag to load it. The <script> tab is placed at the appropriate location in your HTML.
There are several ways to embed the plots in your HTML. I used a server side include, and the section of code looks like this:
<div class="bokeh">
<!--#include file="AV_ratio.tag" -->
</div>
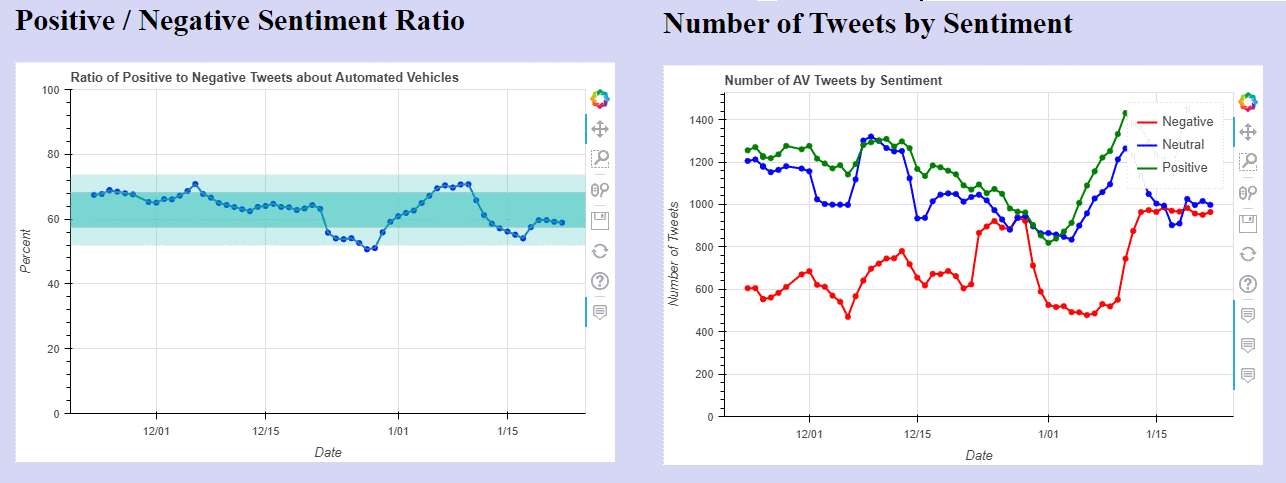
You can see the two plots in the left column of the AV Sentiment Index web page. Static screenshots are shown below:
Initial Observations
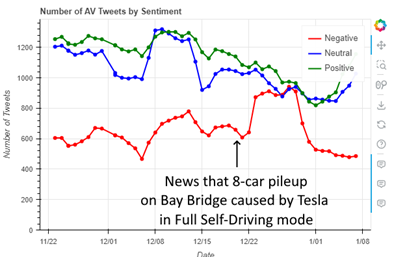
Shortly after I began to capture data, the sentiment regarding automated vehicles dipped sharply for about a week, with the number of negative tweets rising sharply and the positive to negative ratio dropping 2 standard deviations below the mean. In checking what was happening, news had just broken of a major multi-vehicle crash involving a vehicle in self-driving mode. This news was clearly reflected in the negative tweets, with “hot” words that frequently occurred, but had been missing the previous week such as “Bay Bridge,” “Tesla full,” “eight car,” “eight vehicle,” and “vehicle crash.”
Update, 4/23/2024: I’ve now completed this project by publishing two reports analyzing the sentiment data. For those interested, the reports are Seasonality and Variance of Twitter Sentiment Regarding Electric and Automated Vehicles, which looks at the seasonality, variance, long term trends, and skew in the sentiment data, and The Best of Days, the Worst of Days: Twitter Sentiment Regarding Automated Vehicles, which looks at a dozen outlier days, the causes of the extreme sentiment on those days, and the long term impact of these events.